
はじめに
こんにちは、プレックスの池川です。
最近、AI の話題を聞かない日はないと言っても良いくらい AI が身近になりました。 弊社でも ChatGPT、GitHub Copilot を会社負担でエンジニアに配布しており、日々の開発に役立てています。
テスト環境の構築時には大量の画像や写真が必要となることが多く、それらの準備には一定の時間と労力がかかります。 この問題を解決するために、画像生成AIを使用して大量の画像を準備してはどうかと考え、今回、それを検証してみました。 Web UI からでも画像生成は可能ですが、生成できる枚数に上限があり、また保存先が限定されるため、API経由で画像生成を行うスクリプトを作成しました。
この記事では検証する中で得たノウハウについて、共有できればと思います!
【この記事で触れること】
- Stable Diffusion を使って API 経由で画像生成する方法
【この記事で触れないこと】
- 画像生成AIモデルの詳しい説明
- プロンプトやパラメータのこと
実行環境
- Stable Diffusion 2.1
- Stable Diffusion web UI(AUTOMATIC1111)
- Google Colab Pro
手順
1. Google Colab の環境設定を行う
今回は簡単に環境構築ができる Google Colab 上で stable-diffusion-webui を動かしました。 Google Colab の設定は実行環境にまとめていますので参考にしてください。
注意点として Google Colab には無料枠がありますが、UI上で画像生成をする用途だと制限されるため、有料のプランを準備する必要があります。 無料枠のまま stable-diffusion-webui を動かそうとすると下記のような警告のメッセージが表示されます。 日本語の規約には2023年5月29日時点では反映されていなかったため、英語版の規約を確認ください。

2. Stable Diffusion web UI を起動する
Google Colab で下記のコマンドを実行します。最後の行に書かれてある python コマンドのオプションに—-apiをつけることで、APIが実行できます。
# 必要なライブラリをインストールする %pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchtext torchaudio torchdata==0.6.0 --index-url https://download.pytorch.org/whl/cu118 # stable-diffusion-webui のソースコードをクローンしてくる !git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui %cd /content/stable-diffusion-webui # モデルをインストールする !wget https://huggingface.co/stabilityai/stable-diffusion-2-1/resolve/main/v2-1_768-ema-pruned.safetensors -O /content/stable-diffusion-webui/models/Stable-diffusion/sd_v2.1.safetensors # 起動 !python launch.py --share --api --xformers --enable-insecure-extension-access
起動すると、public URL が発行されますのでこちらにアクセスします。 後ほど API を実行する際にもこの URL を使います。
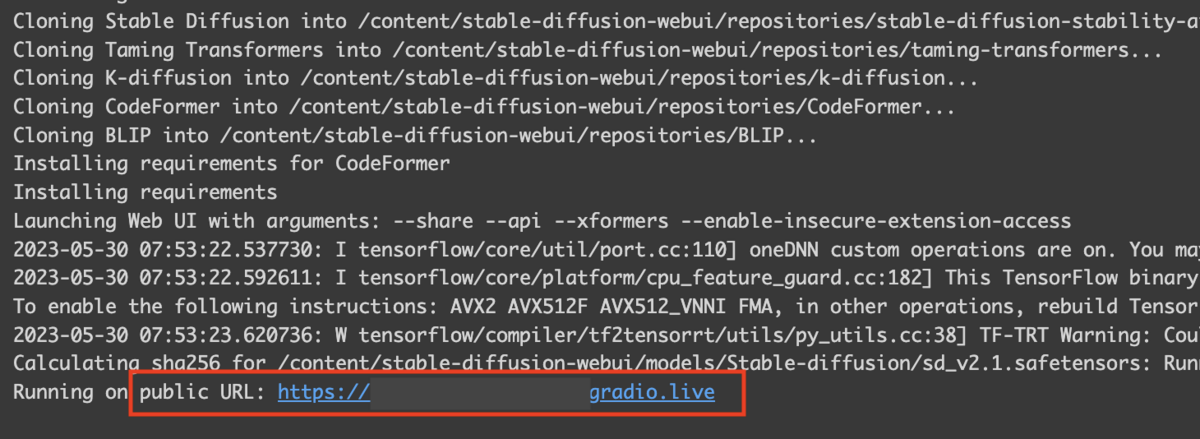
アクセスして下記のような画面になれば起動完了です。
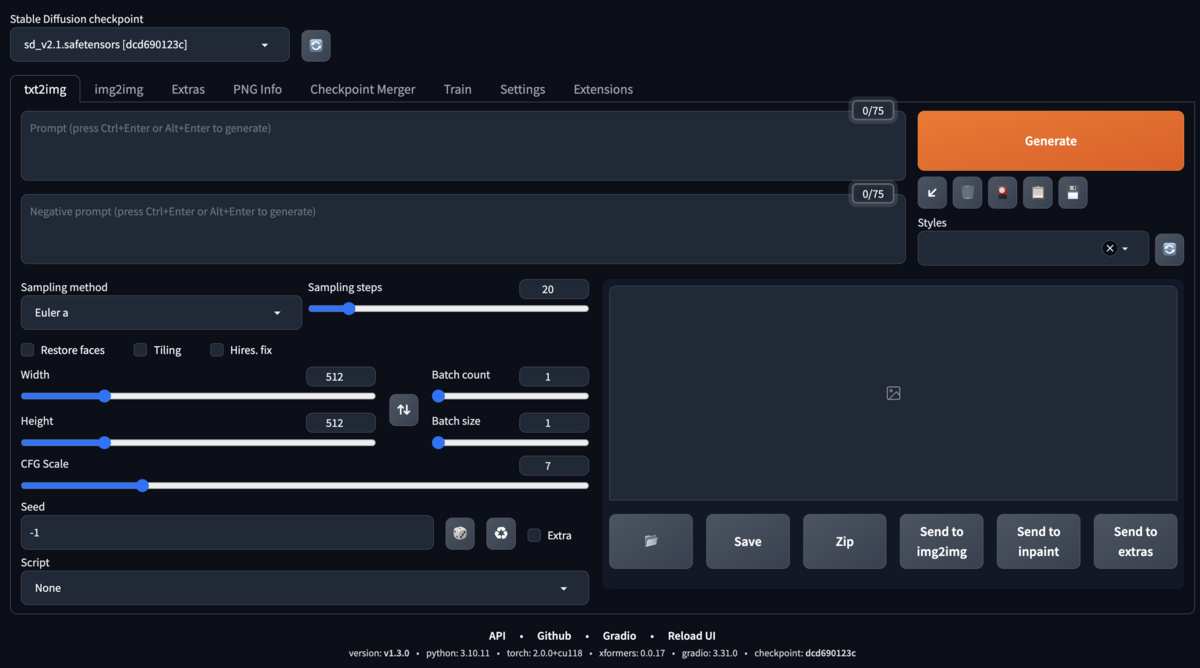
3. API を実行するスクリプトを作成する
続いて画像生成用のスクリプトを作成します。 スクリプトは普段、Rubyを使うことが多いのでRubyで書きました。 public URL と生成したい画像の枚数をオプションで渡すことで、画像を生成後ローカルに保存することができます。
require 'uri' require 'net/http' require 'net/https' require 'json' require 'base64' require 'date' require 'optparse' # コマンドラインオプションをハンドルする def parse_arguments opt = OptionParser.new params = {} opt.on('-i VAL') { |v| params[:i] = v } opt.on('-n VAL') { |v| params[:n] = v } opt.parse!(ARGV, into: params) params end # 画像生成に必要なプロンプトやパラメータを設定する def build_payload { "prompt" => "warehouse entrance", "negative_prompt" => "human", "sampler_name" => "DDIM", "restore_faces" => true, "steps" => 150, "width" => 1200, "height" => 675, } end # リクエストを送信する def send_post_request(uri, payload) Net::HTTP.post(uri, payload.to_json, "Content-Type" => "application/json") end # 画像をローカルに保存する def save_image(data, index) decode_image = Base64.decode64(data["images"][0]) file_name = "#{DateTime.now.strftime('%Y%m%d%H%M%S')}_#{index + 1}.png" File.open("./output/#{file_name}", "wb") do |file| file.write(decode_image) end file_name end # 画像を生成する def create_and_save_images(input_url, number_of_images) uri = URI.parse("#{input_url}/sdapi/v1/txt2img") payload = build_payload number_of_images.times do |i| puts "Generate #{i + 1} image" response = send_post_request(uri, payload) image_data = JSON.parse(response.body) file_name = save_image(image_data, i) puts "Download #{file_name} to local" end end params = parse_arguments create_and_save_images(params[:i], params[:n].to_i)
build_payload メソッドでは画像生成に必要なプロンプトやパラメータを指定しています。
- prompt
- 画像生成系AIでどのような絵を出力して欲しいかを指示する文字列
- negative_prompt
- 排除したい要素
- sampler_name
- restore_faces
- true にすることで顔の崩れを防ぐ
- steps
- ノイズを除去する回数、多いほどノイズが除去されるが生成に時間がかかる
- width、height
- 生成する画像のサイズ
APIの仕様は「public URL/docs」(例:https://1234566789abcde.gradio.live/docs)で確認できますので、そちらを参考にしてください。今回はテキストからイメージを生成したいので、使用するのは「/sdapi/v1/txt2img」です。プロンプトに加えてステップ数が画像のサイズなどが指定できます。
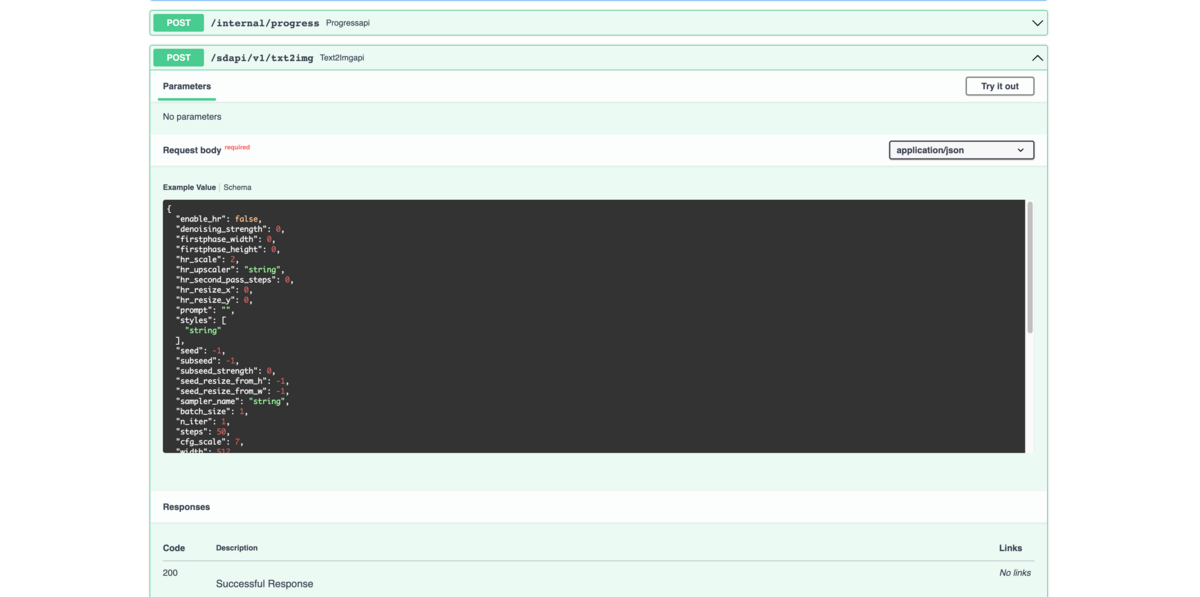
4. スクリプトを実行して画像を生成する
3で作ったスクリプトを実行します。
$ ruby ファイル名 -i https://1234566789abcde.gradio.live -n 100
実行中は Web UI で生成した時と同様に、Colab 上で状況を確認できます。
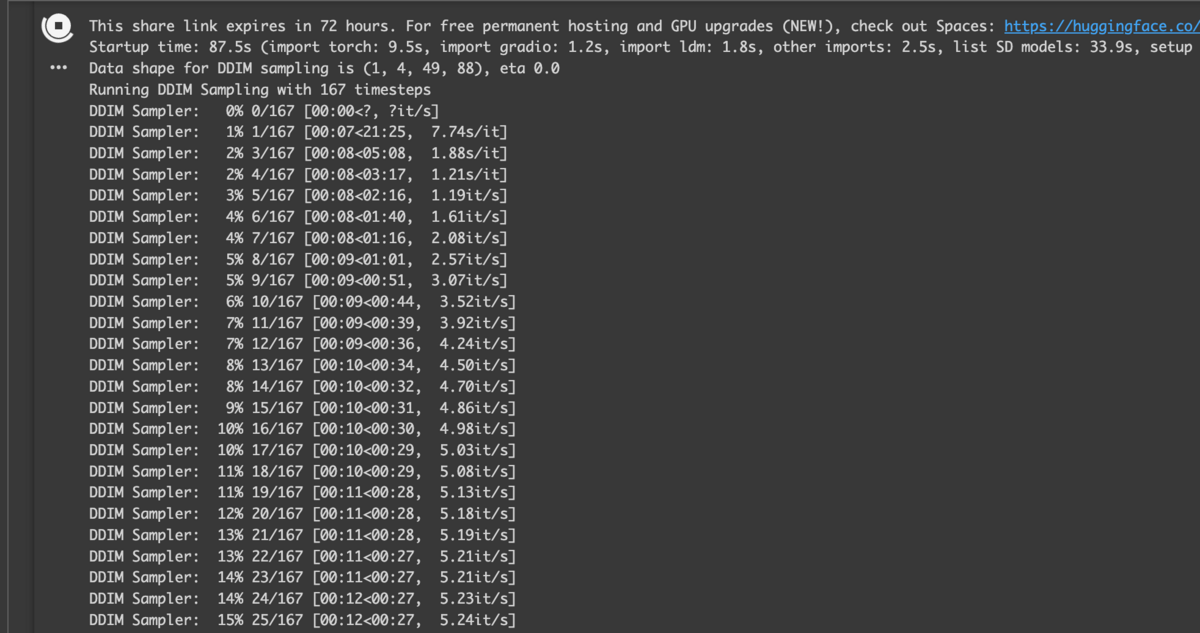
画像生成が完了するとローカルの指定していたディレクトリに画像が保存されています。
生成された画像の一例です。

今回指定した条件だと、100枚の画像を生成でおよそ40分かかりました。また、使用した Google Colab のリソースは9コンピューティングユニットで、費用としては約106円でした。(費用はGoogle Colab のプラン一覧参照)
さいご
本記事では画像生成AIを使ってAPI経由で画像生成する方法について、触ってみて得られたノウハウをまとめました。 はじめて WebUI 上で画像生成したときも面白いなと思いましたが、API経由で画像生成ができることでより幅が広がりそうです。
API 経由で画像生成する方法としては、今回、取り上げたもの以外にも DreamStudio が提供しているStability APIがあり、今後もどのようなことができるかも含め様々な検証を行っていきたいと思います。
最後になりますが、プレックスではソフトウェアエンジニア、フロントエンドエンジニアを募集しています。 ご興味がある方はぜひご応募ください!