
こんにちは。今回は11月7日に開催されたPLEX TechConについて、入社4ヶ月の開発部コーポレートチームの岡田がレポートさせていただきたいと思います。
まず、PLEX TechCon(プレックス テックコン)について軽く説明させていただくと、去年から年1の頻度で開催している株式会社プレックスのエンジニア全員集合の技術カンファレンスです。参加者は雇用形態に関わらず、プレックスで働いたことがある人限定のクローズドなイベントです。
なぜ TechCon を開催するのか?
プレックスではエンジニア組織が拡大しており、隣の人や部署が日々どのような業務に向き合っているかを知る機会は決して多くありません。そこで、お互いの事業や組織でどんな取り組みをしているかを知るための相互理解の場として、また、発表テーマを幅広く設定することで、TSKaigi や Kaigi on Rails に登壇するメンバーが出てきたように登壇練習の機会としても活用してほしいという思いから開催されました。
具体的な業務内容には触れられませんが、各チームが直面した課題や苦労、技術的な議論の雰囲気をお伝えできればと思います。
タイムテーブル
| チーム | 発表者 | タイトル | |
|---|---|---|---|
| 14:00 - 14:25 | プレックスジョブ | 池川 | 倍倍NESTED! |
| 14:25 - 14:50 | プレックスジョブ | 栃川 | 私の個人生産性向上プロジェクト~序章~ |
| 14:50 - 15:15 | プレックスジョブ | 小松 | 運用まで行くぜ!AIがE2Eテストを代行する時代はすでにやってきている?! |
| 15:15 - 15:40 | サクミル | 毛利 | フロントエンド データモデリング -クソデカ画面でデータを扱う流儀- |
| 15:40 - 16:05 | サクミル | 荒木 | 0→1から1→10へ:ユーザー行動データから"使われ方"を可視化する |
| 16:05 - 16:20 | 休憩 | ||
| 16:20 - 16:45 | コーポレート | 山崎 | コーポレートチームの AI アプリケーション開発への取り組み |
| 16:45 - 17:10 | コーポレート | 金山 | SAML認証の仕組みと p-search への導入事例 |
| 17:10 - 17:35 | コーポレート | 宮森 | 気づける安心、直せる体制。Sentry × Kintoneで広がるエラーモニタリング |
| 17:35 - 18:00 | コーポレート | 石塚 | Claude Codeによる開発効率化 |
| 19:00 - 21:00 | 懇親会 19:00開始 |

前半(プレックスジョブ、サクミルチーム)
倍倍NESTED!
最初の発表は、プレックスジョブチーム池川さんによる、クエリのパフォーマンスチューニングについての発表です!

事の発端として、とあるスカウト対象者のユーザーを抽出する処理が45秒のリクエストタイムアウトに引っかかっておりエラーアラートが上がっていました。
クエリの内容としては10以上ある複雑な条件のクエリで、実際に該当クエリを実行したところ約1分30秒かかる事が判明。実行計画を確認すると、Nested Loopの中にさらにNested Loopがネストしており、まさに「倍倍NESTED!」状態というところから話が始まりました。
実行計画を確認すると「7.2千件 × 13.3万件 = 約9億6千万件」という膨大な「Rows Removed by Join Filter」が発生しており調査の結果、原因は複数の要素にありました。
- 実行計画の見積もりと実際の行数に乖離があるにも関わらずNested Loopが採用され、大量のNested Loopが発生していた。
- CTEの元テーブルにはインデックスが貼られていたが、MATERIALIZEDされることで元のインデックスが引き継がれていなかった。
これら二重の落とし穴が引き金となってスロークエリが発生していましたが、最終的にはJOINを使う形に改修することで、1分半かかっていたクエリを数秒まで改善できたというお話でした。

SQLの結合アルゴリズムに「Nested Loop」「Merge」「Hash」の3種類があることや、CTEがMATERIALIZEDされるかどうかで挙動が大きく変わることなど、非常に学びの多い発表で大変勉強になりました!
今回初めてCANDY TUNEの「倍倍FIGHT!」という曲を知ったのですが、池川さんのスライドサムネが「倍倍NESTED!」になっているので、どうやってサムネを作ったんだろうと気になっています
私の個人生産性向上プロジェクト~序章~
同じくプレックスジョブチームの栃川さんからは、生産性向上についての発表です。

開発時の姿勢から整理整頓、便利ツール、ショートカットまで多岐にわたる内容でとても面白かったです!
よく開きっぱなしにしがちなブラウザのタブを自動で削除できる「Tab Wrangler」のようなツールや、「Shift + Command + (N or G or S)」でNotion、Google、Slackを開けるショートカットコマンドは、早速試してみたいと思いました。
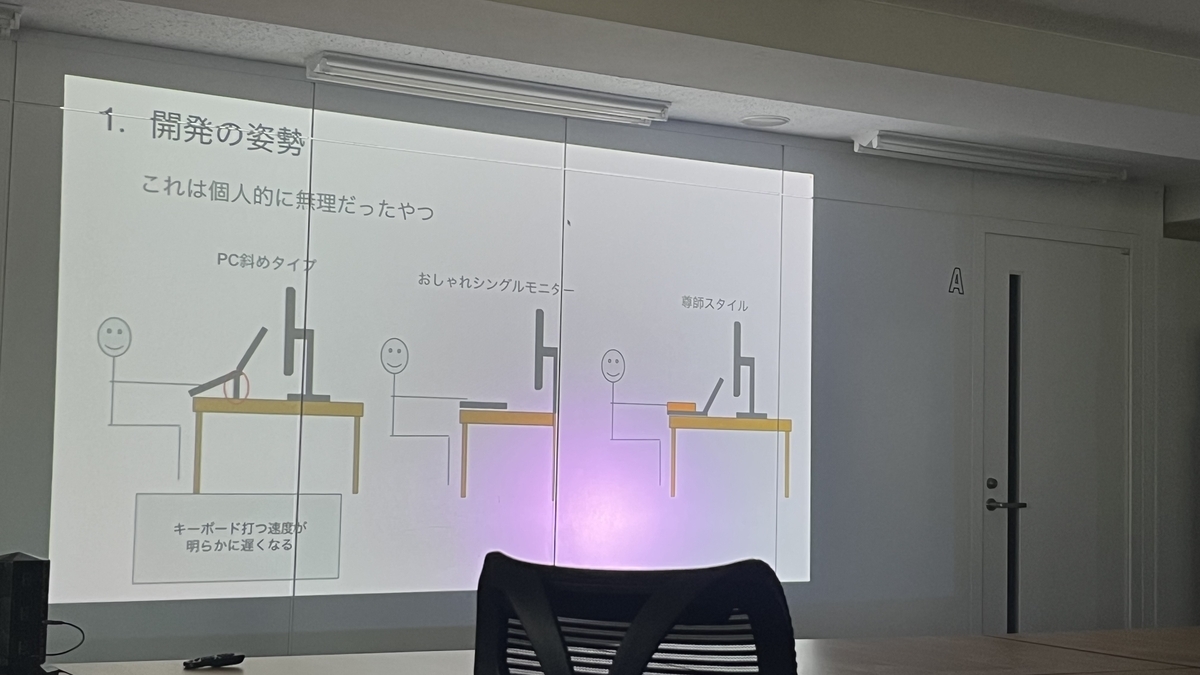
私も普段、知っているコマンドだけで作業しがちなので、常にショートカットを意識していきたいです!
運用まで行くぜ!AIがE2Eテストを代行する時代はすでにやってきている?!
続いてプレックスジョブチームの小松さんの発表です。

前回はDevinを使ったE2Eテストに挑戦したものの、燃費が悪く運用には至らなかったというお話でした

今回はその続きで、固有のエージェントに囚われず「テスト仕様書」を資産として活用し、AIによるE2Eテストの代行と運用を目指すといった内容です!
PJ(プレックスジョブ)チームでは、売上に直結する機能のリグレッションテストやシナリオがあり、繰り返し実行する必要があるものの、運用が形骸化しがちという課題がありました。これを解消するためにE2Eテストを自動化したいというのが今回の事の背景となります。
話の内容としてはまず前回Devinに作成させたテストガイドやテスト仕様書を再度メンテナンス。WEBページの操作にChromeDevToolsを使用させ、テスト仕様書を基にテストを実施。Claude Code(Claude Sonnet 4)、Codex(GPT-5-codex)、Copilot(Claude Sonnet 4)の各エージェントの違いを比較してみたといった内容です。
結論として「誰かができたことは誰でもできる。誰かが躓いたところはみんな躓く」ということで、概ねAIエージェント間のレベル差はなくなっているようです!

さらに複雑性の高いテストを実施したところ、ChromeDevToolsからは操作できないUI要素の存在や、ローカルマシンのリソースに依存するため並列でのテストの難しさといった課題があるものの、ローカルAIエージェントを使ったE2Eテストは現実的な段階まで来ているとのことで、自分も簡単なテスト仕様書を作ってみてトライしてみたいです!
フロントエンド データモデリング -クソデカ画面でデータを扱う流儀-
続いてサクミルのtettyさんによる、フロントエンドのパフォーマンスチューニングについての発表です。


皆さん「トリレンマ」をご存知でしょうか?三つのうちどれか一つを選ばなければならない状況を指すそうなのですが、「パフォーマンス」「拡張性」「可読性」の3つを同時に改善するのは難しいですよね?そんな「トリレンマ」を改善したお話です。
プレックスでは建設業界向けの現場管理ツールとして「サクミル」というサービスを提供しています。直近、サクミルではこれ一つでサービスが完結するほどの規模感の見積もり機能をリリースしました。
しばらくして、ユーザーさんから「見積もり作成時に項目が増えると重くなる」「見積もり入力が重くなった場合の改善策はありますか?」といった問い合わせが来るようになりました。そこから、計測、分析、データモデリング、改善までの一連の流れが紹介されました。

Chrome DevtoolのPerformanceタブを使って、JSの処理(Scripting)が原因か、DOMの描画(Rendering)が原因かのアタリの付け方や、Performance APIを使って各処理の実行時間を計測するなど、まさにお手本のような調査手順でした!
根本的な原因として、見積もり項目や明細のデータの持ち方が階層構造のままであったため、親要素や子要素が変更されるたびに再描画・再マウントが発生していた点や、見積もり項目の計算効率や探索方法が非効率だった点にありました。
そこで改めてデータモデリングを行い、フラットなデータ構造に変える事で、階層構造時に存在したUIとロジックの共存によって引き起こされていた不要な計算処理によるパフォーマンス悪化や、コンポーネントのmemo化による拡張性低下の問題を無事解決したという話です。

実際に開発・リリースしてみると、想定外の使い方をされていたり、想定以上のデータが登録されていたりすることがあるので、私も常に「パフォーマンス」「拡張性」「可読性」の3つを意識して実装していきたいなと感じました!
0→1から1→10へ:ユーザー行動データから"使われ方"を可視化する
サクミルチームからはもう一人、荒木さんからサービスリリース後の「1→10」フェーズにおけるデータ活用の取り組みについての発表です。

Firebase AnalyticsやBigQuery、dbtといったツールを活用し、イベントごとのタイムスタンプを計測することで、「誰が」「どのページを」「どれくらいの時間見ていたか」をデータとして割り出し、ページ導線の最適化や離脱パターンの把握を通じてKPI改善に繋げたり、オンボーディング完了率の改善に繋げたという内容です。
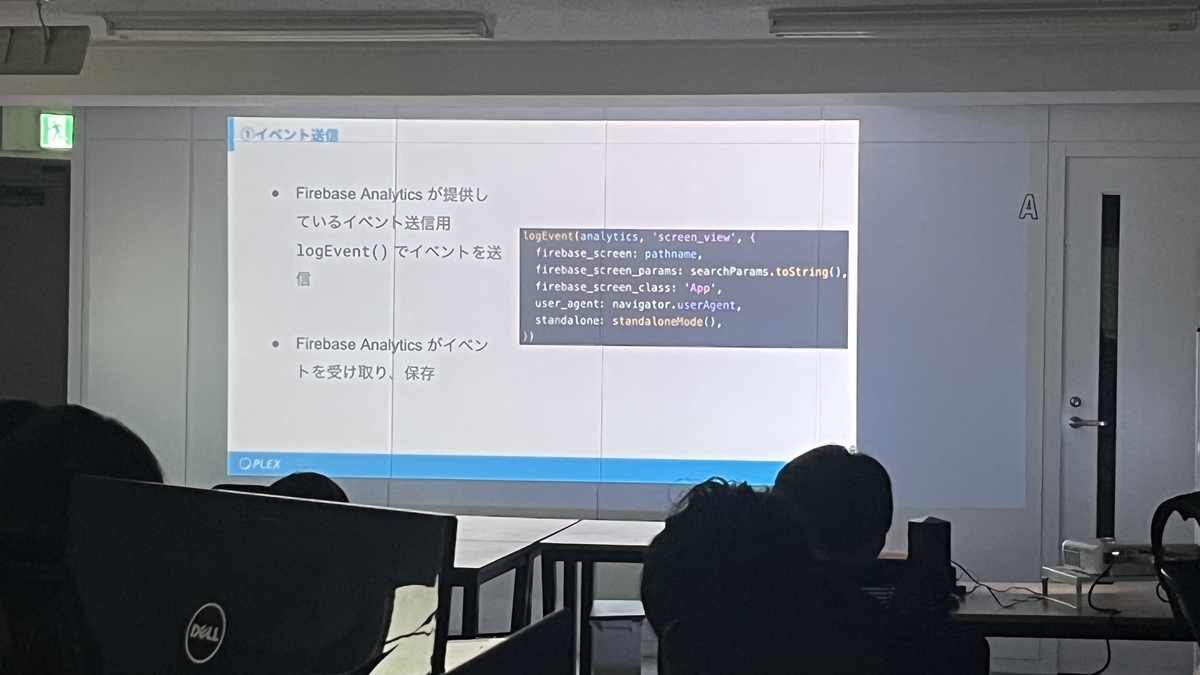
それに至るまでの地道な計測や集計と計算が必要であったり、データをただ計測するだけでなく、それをいかに事業改善に「活用」するかという一連の流れがよく分かる、非常に学びになる発表でした!

ゲスト
休憩時間には、ゲストとして駆けつけてくださった元インターン生の3名に軽く自己紹介をしていただきました。
現プレックスの主要メンバーの元同期の方や、CEOの黒崎さんとシェアハウスをしていた時代を知るOBの方など、豪華なメンバーから貴重なお話を伺うことができました。鈴木さん、豊田さん、内藤さん、お忙しい中お越しいただきありがとうございました。



後半(コーポレート、マーケティングチーム)
コーポレートチームの AI アプリケーション開発への取り組み
コーポレートチームの山崎さんからは、実際の業務へのAI活用に関する取り組みの発表です。具体的な事例として
- ①フォーマットがバラバラな求人情報を構造化して保存
- ②架電内容(音声ファイル)を要約する
- ③要約した架電を元にメールを作成
といった3つの具体例を元に、どのようにAIを取り入れていったかが紹介されました。

当初は多機能なAIアプリケーションフレームワーク「Mastra」を利用して開発していましたが、様々なAI活用に取り組む中で、最終的に必要だったのは出力の構造を定義できるStructured Outputs機能でした。
これはMastraを使わずともどのAIモデルも対応しており、シンプルなOpenAI Agents SDKだけでも必要な要件を満たせるというお話でした。

私もMastraについては聞いたことがあり気になっていましたが、今回の発表で具体的にどのような使い方ができ、何が実現できるのかを知ることができ、非常に学びになりました!
その他にも、AI導入におけるコスト最適化の難しさ(安いモデルで5割の精度を目指すか、高いモデルで8割の精度を目指すか)や、ロジックを含めたテスト、不確実性のある出力データをシステムにどう組み込むかといったリアルな課題を聞けて良かったです!
SAML認証の仕組みと p-search への導入事例
続いてコーポレートチームの金山さんからは、社内システムへのSAML認証導入についての発表です。

現在プレックスでは、自社で開発している「p-search」というM&Aに関する社内システムが存在します。M&Aシステムであるため機密情報が多く、従来のID・パスワード認証ではID/PWさえ知っていればどこからでも誰でもログインできてしまうというセキュリティ上の課題がありました。
そこで、端末認証や社内からのアクセス制限が可能なCloudGateというSSOプラットフォームを導入し、セキュリティを強化したという内容です。

SAML認証の基本的な仕組みや、元々利用していたFirebase Authenticationと連携することで意外と簡単に導入できた点など、SAML認証は敷居が高いイメージがありましたが、今回のスライドで認証周りを触れることへのハードルが一段下がりました!

金山さんのスライドは、デザイナーである奥様も手伝ってくださったそうで、非常に読みやすくまとまっていました。デザインの力はやはりすごいですね。
気づける安心、直せる体制。Sentry × Kintoneで広がるエラーモニタリング
続いてコーポレートチームの宮森さんからはSentry導入に関する発表です。


プレックスではKintoneアプリを使った業務フローが数多く存在し、現状は問い合わせベースで対応しているという課題がありました。そんな「見えないエラー」をいかに検知し、修正・改善できる体制を整えるかという課題に取り組んだ内容です。
実際にSentryを導入してみると、Kintoneアプリ以外のGoogle APIライブラリなどのエラーも検知してしまったり、無料枠のイベントが5,000件であるため、いかにサンプリングやフィルタ設計を行うかといった具体的な話も聞けました。
現在私が関わっているp-searchにもぜひ導入してみたいと思いました!

Claude Codeによる開発効率化
最後の発表はコーポレートチームの石塚さんによる、Claude Codeを活用した開発効率化に関する取り組みです。

話の内容はあまり細かくお伝えする事はできませんが、Claude.mdの作成から、ガイドラインやドキュメントの整備、Claude Codeのカスタムコマンドを取り入れることで大幅に開発効率をUPさせることに成功したというお話でした。

特に、定型作業のためのプロンプトやPull Requestを集めたナレッジ集を作成することで開発効率をさらにUPさせたりと、すぐにでも真似できる実践的なアイデアが多く、非常に参考になりました!
懇親会
カンファレンスの後は、神田のおしゃれなバルで懇親会です
普段なかなか話す機会のない他チームのメンバーと、それぞれのサービスならではの苦労話や面白いエピソードを聞けて楽しかったです!



最後に、本イベントを企画してくださった石塚さん、懇親会の幹事を務めてくださった高岡さん、そしてこの日のためにスライドを作成して発表してくださった皆さん、本当にありがとうございました。