こんにちは、Plex Job 開発チームの高岡です。
先日 PLEX TechCon 2025 が開催されました。
▼ 当日の様子はこちらPLEX TechCon 2025 レポート - PLEX Product Team Blog
はじめに
以前のプロジェクトで、本番環境の一部の処理だけがやたらと遅くなるスロークエリに遭遇しました。ボトルネック の特定と改善に取り組み、実行計画を確認したのですが、決定的な原因までは絞り込めていませんでした。
行き詰まってしまったため、切り口を変えて Cloud SQL (PostgreSQL )のログから、スロークエリが発生している時点の DB の状態を見ることにしました。PostgreSQL のどの仕組みと結びついているのかを把握するために、PostgreSQL のアーキテクチャ
本記事では、当時実際に確認していた次の3種類のログメッセージを題材に、ログが出力されたときに PostgreSQL の内部で何が起きているのかを整理します。
チェックポイント処理のログ
自動バキューム処理のログ
TEMP 落ちのログ
また、特に「3.TEMP落ちのログ」からスロークエリのパフォーマンス改善につなげることができたので、その事例も合わせて紹介します。
ログと PostgreSQL のアーキテクチャ を手がかりに、結果として「実行計画だけを見ていたときには分からなかったボトルネック 」を発見できた、という経験をもとにまとめています。普段なんとなく PostgreSQL を使っているものの、内部構造はいまいちピンときていない ……という方の、理解を一歩進めるきっかけになればうれしいです。
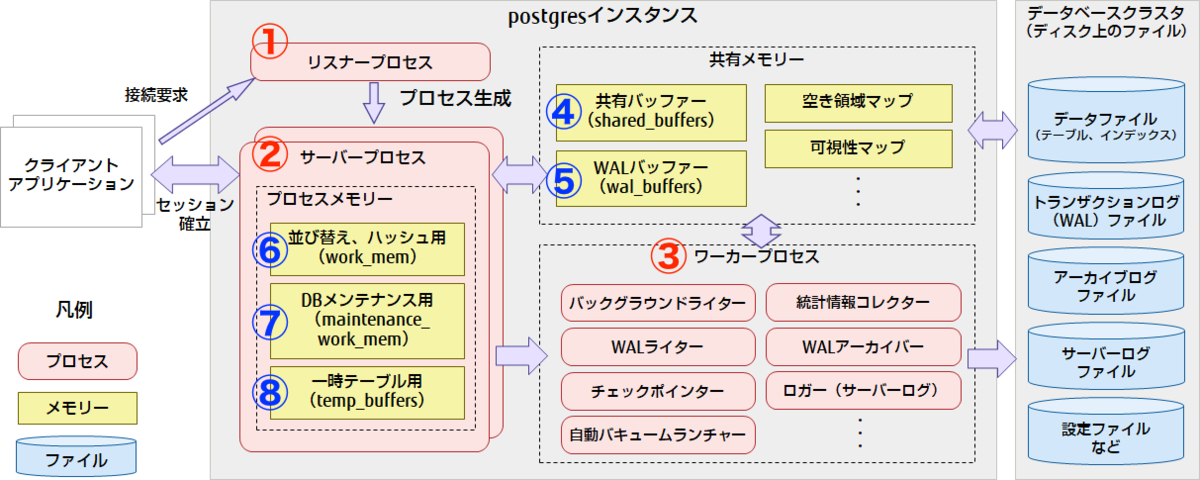
まずはじめに、先ほど挙げた 3 つのログがそれぞれ PostgreSQL のどの構成要素と関係しているのかをイメージしやすくするために、全体の構成図を簡単に見ていきます。
出典 : PostgreSQLのアーキテクチャー概要|PostgreSQLインサイド : 富士通
プロセス構成(全体図の赤の要素)
PostgreSQL はマルチプロセス構成で、
① リスナープロセス
② サーバープロセス
③ ワーカープ ロセス
の主要な3つのプロセスが存在します。PostgreSQL を制御するさまざまなプロセスをフォークして起動する親プロセスです。カープ ロセスは、本記事でも説明する「チェックポインター 」や「自動バキュームランチャー」などの PostgreSQL の重要な作業を担うプロセス群です。MySQL では、mysqldと呼ばれるプロセスの中にいくつかのスレッドを起動させるマルチスレッド構成にて動作しています。
メモリ構成(全体図の黄色の要素)
PostgreSQL のメモリは、PostgreSQL 全体が使用する領域で共有される共有メモリ域 と、サーバープロセスごとに確保されるプロセスメモリ域 の大きく2つに区別されます。
▼ 共有メモリ域
④ 共有バッファー(shared_buffers)
テーブルやインデックスのデータをキャッシュする領域
⑤ トランザクション ログバッファー(wal_buffers)
▼ プロセスメモリ域
⑥ 作業メモリ(work_mem)
クエリ実行時に行われる、並び替えとハッシュテーブル操作のために使われる領域
⑦ メンテナンス用作業メモリ(maintenance_work_mem)
⑧ 一時バッファ(temp_buffers)
サーバープロセスごとに作成される一時テーブルにアクセスするときに用いられる領域
MySQL でも名称は異なりますが、似たような用途のメモリ領域が用意されています。
今回見ていくログは、この構成の「どこで 」「何を行っているか 」をそれぞれ示すものになります。
調査した3つのログ
先ほど見た構成図と対応させながら、実際に Cloud SQL のログに出ていたメッセージを 3 種類取り上げていきます。
checkpoint starting / checkpoint complete
automatic vacuum of table ...
temporary file: path ...
どれも それ自体がDBサーバーの動作上の不具合 ではありません。ボトルネック となっているクエリのパフォーマンスチューニングに活かせるようになります。
1. チェックポイント処理のログ📝
2025-07-07 18:20:47.160 UTC [31]: [5831-1] db=,user= LOG: checkpoint starting: time
2025-07-07 18:20:47.509 UTC [31]: [5832-1] db=,user= LOG:
checkpoint complete: wrote 5 buffers (0.0%); 0 WAL file(s) added, 0 removed, 0 recycled;
write=0.318 s, sync=0.008 s, total=0.350 s; sync files=3, longest=0.005 s, average=0.003 s;
distance=23 kB, estimate=363 kB; lsn=DE/2F0C6B78, redo lsn=DE/2F0C6B40
※ 数値は当時のログと異なります。
概要
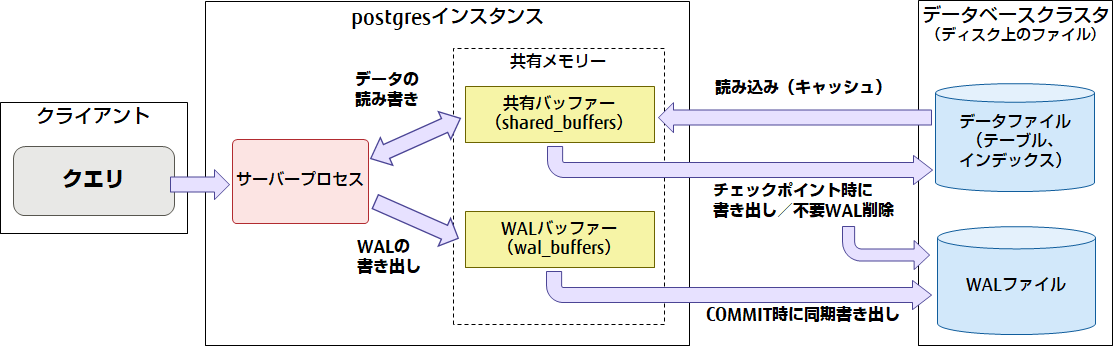
PostgreSQL では、テーブルやインデックスを更新するとき、まずは共有メモリ域の共有バッファー上のページを書き換えつつ、更新内容だけを トランザクション ログ(WAL)バッファーに順次書き込む構成になっています。
WAL(Write Ahead Logging)は、PostgreSQL の更新内容を順次記録していくログで、障害復旧やストリーミングレプリケーション で利用される非常に重要な情報です。
COMMIT 時にディスクへ書き出されるのは、基本的にはこの WAL だけであり、データファイル本体への書き込みはあとからまとめて行われます。
これにより更新処理自体は「メモリと WALへの追記」が中心になるため高速に処理できるようになります。
しかしそのまま放置すると、
共有バッファー上に「ディスクへまだ書き出していない更新済みページ(ダーティページ)」が増えていく
障害復旧に必要な WAL ファイルもどんどん溜まっていく
という問題が発生します。
共有バッファー上の更新済みページ(ダーティページ)をデータファイルへ書き出す
その時点の WAL 位置に「チェックポイントレコード」を記録し、それ以前の WAL セグメントを削除・再利用できる状態にする
という役割を担っています。
これを実際に行っているのは、前半の「PostgreSQL の構成」の章で触れた、ワーカープ ロセスの1つである「チェックポインター プロセス」が動作しています。
全体の構成とデータの流れのイメージ図は下記になります。
出典 : パフォーマンスチューニング9つの技 ~「書き」について~|PostgreSQLインサイド : 富士通
このような全体の仕組みによって、「データベースの更新処理の高速化」と「障害発生時のデータ保証」を両立して実現しています。
チェックポイントは、通常以下のような条件のいずれかを満たすと実行されます。
checkpoint_timeout で設定された時間が経過したとき直近のチェックポイントから生成された WAL の量が、max_wal_size に近づいたとき
手動で CHECKPOINT コマンドを発行したとき、など
今回のログの checkpoint complete 行からは、少なくとも次のようなことが分かります。
wrote 5 buffers (0.0%) … チェックポイント中に 5 ページだけ書き出されているwrite=0.318 s, sync=0.008 s, total=0.350 s … トータルで0.35 秒でチェックポイント処理を完了distance=23 kB, estimate=363 kB … 前回チェックポイントから今回までに発生した WAL が 23kB 、見積もり値(estimate)も数百 kB
このログだけを見る限り、チェックポイントそのものは比較的軽く、ボトルネック にはなっていない状態だと読み取れます。
チューニングポイント
チェックポイント間隔を 短く すると
リカバリ 時間は短くなるその代わりチェックポイント処理(バッファ書き出し)の頻度が上がり、書き込み I/O のオーバーヘッドが増える
チェックポイント間隔を 長く すると
リカバリ には時間がかかる代わりに I/O のオーバーヘッドは減り、平常時のスループット が上がる可能性がある
というトレードオフ があることを認識しておく必要があります。
チェックポイント処理を行う間隔を時間で指定するcheckpoint_timeout パラメータがあります。
このパラメータのデフォルト値は5分ですが、こちらは間隔が短くI/Oのオーバーヘッドが増えるため、PostgreSQL のチューニング記事などでは、30 分前後に調整していくケースがよく紹介されています。
もちろんアプリケーションの特性にもよるので、更新処理が多いアプリケーションの場合は、トランザクション ログ量が多くなるため、checkpoint_timeout を長めに設定すると、その分リカバリ ー時間も増加する問題が発生します。
28.5. WALの設定
2. 自動バキューム処理のログ 🧹
2025-07-07 03:03:26.892 UTC [236223]: [1-1] db=,user=
LOG: automatic vacuum of table "postgres.public.filtered_job_salaries": index scans: 1
pages: 0 removed, 1169 remain, 1169 scanned (100.00% of total)
tuples: 48028 removed, 50752 remain, 0 are dead but not yet removable
removable cutoff: 95920778, which was 15 XIDs old when operation ended
new relfrozenxid: 95917748, which is 127978 XIDs ahead of previous value
new relminmxid: 83348, which is 1 MXIDs ahead of previous value
frozen: 0 pages from table (0.00% of total) had 0 tuples frozen
index scan needed: 601 pages from table (51.41% of total) had 50756 dead item identifiers removed
index "filtered_job_salaries_pkey": pages: 425 in total,
139 newly deleted, 284 currently deleted, 145 reusable
....
I/O timings: read: 138.823 ms, write: 0.000 ms
avg read rate: 2.515 MB/s, avg write rate: 2.503 MB/s
buffer usage: 4975 hits, 208 misses, 207 dirtied
WAL usage: 3179 records, 205 full page images, 2084441 bytes
system usage: CPU: user: 0.13 s, system: 0.01 s, elapsed: 0.64 s
※ 数値は当時のログと異なります。
概要
PostgreSQL は MVCC(Multi-Version Concurrency Control)という方式で同時実行制御を行っています。テーブルサイズの肥大(bloat)や統計情報の劣化 を招きます。
これを定期的に掃除してくれるのが VACUUM であり、その自動実行を担うのが autovacuum の機構です。
autovacuumはワーカープ ロセスの1つである、「自動バキュームランチャープロセス」で制御/実行されます。
デフォルトでは、「総行数の 20% + 50 行 」程度の更新があると autovacuum が走る、といった設定になっています(autovacuum_vacuum_scale_factor / autovacuum_vacuum_threshold などで調整可能)。
上記の autovacuum ログからは、テーブル "postgres.public.filtered_job_salaries" に対する自動 VACUUM の内容が記載されています。
tuples: 48028 removed, 50752 remain
約 4.8 万行の dead tuple が物理的に削除
index "filtered_job_salaries_pkey": pages: 425 in total, 139 newly deleted, 284 currently deleted, 145 reusable
主キーインデックスは 425 ページ分
139 ページ分で今回新たに削除
合計 284 ページが「削除済み」としてマーク
145 ページは再利用可能な領域として扱える状態になっている
system usage: CPU: user: 0.13 s, system: 0.01 s, elapsed: 0.64 s
といったことが分かります。
チューニングポイント
autovacuum のログ自体が出ていることは問題ありません。
一方で、以下のような場合はチューニングを検討する価値があります。
特定の大きなテーブルに対して autovacuum が頻繁に走っている
autovacuum_vacuum_scale_factor / autovacuum_analyze_scale_factor をテーブルごとに調整し、
更新が多いテーブルはしきい値 を下げて「こまめに掃除」
更新が少ない大きなテーブルはしきい値 を上げて「頻度を下げる」
1 回あたりの autovacuum が何十秒〜数分単位で長時間化している
テーブルの肥大化が進みすぎていないか確認
必要に応じて VACUUM (FULL) や REINDEX などのメンテナンスを検討
まずは「どのテーブルに」「どのくらいの時間」「どれくらいの頻度で」autovacuum が走っているかを可視化するところから始めると、チューニングすべきテーブルの当たりをつけやすくなるかと思います。
24.1. 定常的なバキューム作業
3. TEMP落ちのログ 💣
INFO 2025-07-07T06:02:38.305257Z 2025-07-07 06:02:38.304 UTC [2212337]: [5-1]
db=XXX,user=XXX LOG: temporary file:
path "base/pgsql_tmp/pgsql_tmp2212337.6", size 3427592
※ 数値は当時のログと異なります。
概要
「 PostgreSQL の構成」の章で説明したとおり、PostgreSQL のメモリ構成は大きく「共有メモリ域」と「プロセスメモリ域」に分けられます。作業メモリ(work_mem) は「プロセスメモリ域」の 1 つで、各クライアントセッションごとに確保され、主に次のような操作で使用されます。
ソート操作:ORDER BY、DISTINCT、マージ結合
ハッシュテーブル:ハッシュ結合、ハッシュ集約、メモ化(memoize)ノード、IN 副問い合わせのハッシュ処理
これらの処理が work_mem の上限を超えるデータ量
上記のログメッセージからは、少なくとも 約 3.3 MB の一時ファイルが作成された ことが分かります。work_mem に対して多すぎる可能性を疑うきっかけになります。
チューニングポイント
TEMP落ちを抑えるための基本的なアプローチは、work_mem の上限を調整することwork_mem の値を大きくしすぎると、OS 側で利用できるメモリが減り、その結果としてシステム全体の遅延やメモリ不足(OOM)の発生につながるリスクがあります。
ざっくりとした上限の目安としては、
(物理メモリ - shared_buffersの値) / max_connectionsの値
で算出された値です。
また PGTune の設定値を算出してくれるツールを使用して上限値の目安を把握することを推奨します。
実際には、これらの算出した上限を参考にしつつ、
グローバルな work_mem を少しずつ上げてみる
特定の重い処理だけ、トランザクション 内で SET LOCAL work_mem = '64MB'; のように一時的に増やす
といった運用で調整するのが安全かと思います。
19.4. 資源の消費
work_memを増強してみた
今回はソート処理を行なっていたスロークエリがあったので、work_mem を増加させる検証を行いました。
work_mem の増加方法は、対象の重いクエリだけ、トランザクション 内での設定値を一時的に上げる 方針としました。
まず初めに現在の PostgreSQL の設定値を確認し、
メモリ: 16GB(16,384 MiB)
work_mem : 4MB
max_connections:500
shared_buffers:5,460 MB(5,332 MiB)
上記の設定値からざっくり許容できる work_mem の値を計算します。
(物理メモリ - shared_buffersの値) / max_connectionsの値
(16,384 MiB − 5,332 MiB)/ 500 ≒ 22.1 MiB
この例では、1 セッションあたり 20MB 程度の上限になります。
そして、実際にRuby on Rails で対象のクエリだけトランザクション 内で20MBに増加させてみました。
ActiveRecord ::Base .transaction do
ActiveRecord ::Base .connection.execute(" SET LOCAL work_mem = '20MB' " )
Model .heavy_query
end
この結果、一部のクエリで発生していた TEMP落ちのログが消え、全体で数分かかっていたクエリが 数十秒前後に収まるようになりました 🎉
実行計画で見てみる
簡単なSQL で実際にどのような実行計画の違いが出るのかを見てみます。SQL は下記になります。
EXPLAIN
ANALYZE
SELECT
*
FROM
table_1
JOIN table_2 ON table_1.id = table_2.id
ORDER BY
table_1.id
まずは、デフォルト値の work_mem (4MB)のまま実行します。
結果は下記のようなプランになりました。
QUERY PLAN
Gather Merge (cost=31095.13..40212.57 rows=78144 width=745) (actual time=441.110..721.817 rows=70571 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=30095.11..30192.79 rows=39072 width=745) (actual time=417.967..433.232 rows=23524 loops=3)
Sort Key: table_1.id
Sort Method: external merge Disk: 18776kB 👈👈 注目すべき箇所
Worker 0: Sort Method: external merge Disk: 15096kB
Worker 1: Sort Method: external merge Disk: 12280kB
-> Parallel Hash Join (cost=1790.14..14158.12 rows=39072 width=745) (actual time=44.093..279.160 rows=23524 loops=3)
Hash Cond: ((table_2.id)::text = (table_1.id)::text)
-> Parallel Seq Scan on table_2 (cost=0.00..12180.64 rows=71364 width=543) (actual time=0.045..154.770 rows=57091 loops=3)
-> Parallel Hash (cost=1405.06..1405.06 rows=30806 width=202) (actual time=43.465..43.467 rows=17457 loops=3)
Buckets: 65536 Batches: 1 Memory Usage: 9408kB
-> Parallel Seq Scan on table_1 (cost=0.00..1405.06 rows=30806 width=202) (actual time=0.022..15.490 rows=17457 loops=3)
Planning Time: 0.521 ms
Execution Time: 729.775 ms
注目すべき箇所は、「Sort Method: external merge Disk: 18776kB 」 です。
この「Disk: 18776kB」が、約 18MB 分がメモリからディスクにあふれている(= TEMP落ちしている) ことを表しています。
次に、work_mem を増加させて再度実行計画を取得します。Rails の実装と同じく、トランザクション 内で一時的に work_mem を上げます。
BEGIN ;
SET LOCAL work_mem = ' 20MB ' ;
EXPLAIN
ANALYZE
SELECT
*
FROM
table_1
JOIN table_2 ON table_1.id = table_2.id
ORDER BY
table_1.id
COMMIT ;
結果は下記のようなプランになりました。
QUERY PLAN
Gather Merge (cost=31095.13..40212.57 rows=78144 width=745) (actual time=410.376..494.698 rows=70571 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=30095.11..30192.79 rows=39072 width=745) (actual time=388.172..398.945 rows=23524 loops=3)
Sort Key: table_1.id
Sort Method: quicksort Memory: 17883kB 👈👈 注目すべき箇所
Worker 0: Sort Method: quicksort Memory: 13548kB
Worker 1: Sort Method: quicksort Memory: 17818kB
-> Parallel Hash Join (cost=1790.14..14158.12 rows=39072 width=745) (actual time=47.379..289.016 rows=23524 loops=3)
Hash Cond: ((table_2.id)::text = (table_1.id)::text)
-> Parallel Seq Scan on table_2 (cost=0.00..12180.64 rows=71364 width=543) (actual time=0.316..140.737 rows=57091 loops=3)
-> Parallel Hash (cost=1405.06..1405.06 rows=30806 width=202) (actual time=46.256..46.258 rows=17457 loops=3)
Buckets: 65536 Batches: 1 Memory Usage: 9408kB
-> Parallel Seq Scan on table_1 (cost=0.00..1405.06 rows=30806 width=202) (actual time=0.032..15.850 rows=17457 loops=3)
Planning Time: 0.487 ms
Execution Time: 498.724 ms
今度は 「Sort Method: quicksort Memory: 17883kB」 となっており、ソート処理がディスクではなくメモリ上だけで完結している ことが分かります。
もちろん work_mem を無闇に上げると、「3. TEMP落ちのログ 💣」の章で記載したとおり、
OS 側で利用できるメモリが減り、その結果としてシステム全体の遅延やメモリ不足(OOM)の発生につながるリスク
があるので、
まずはクエリ自体の見直し(不要なソート・巨大な IN・複雑なJOIN など)
それでも厳しいところにだけ、SET LOCAL work_mem をピンポイントで適用
といった順番で検討するのが安全だと思います。
まとめ
本記事では、
チェックポイント処理のログ 自動バキューム処理のログ TEMP落ちのログ
の3つのログを入り口に、PostgreSQL のアーキテクチャ の基本を整理して見ました。PostgreSQL には他にもたくさんのパラメータがあり、他の RDB 製品(MySQL / SQL Server / Oracle など)と比較しながら読むと、設計思想の違いが見えてきて面白い です。
来年の TechCon では、さらに PostgreSQL の内部構造を深掘り、理解しているからこそわかるチューニング事例を紹介したいと思います 🔥
参考
19.4. 資源の消費 24.1. 定常的なバキューム作業 28.5. WALの設定 PostgreSQLのアーキテクチャー概要|PostgreSQLインサイド : 富士通 パフォーマンスチューニング9つの技 ~「書き」について~|PostgreSQLインサイド : 富士通 パフォーマンスチューニング9つの技 ~「基盤」について~|PostgreSQLインサイド : 富士通 [改訂3版]内部構造から学ぶPostgreSQL―設計・運用計画の鉄則 (Software Design plus) | 上原 一樹, 勝俣 智成, 佐伯 昌樹, 原田 登志 |本 | 通販 | Amazon