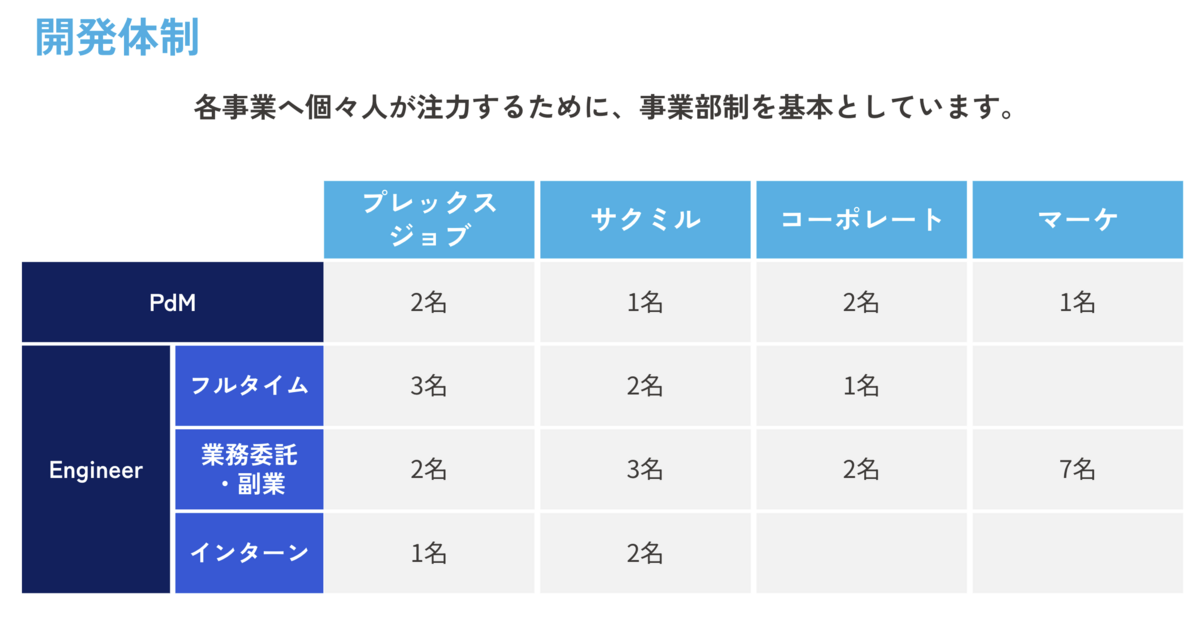
私は、一般的にプロダクトマネージャーとWebマーケティング と言われる役割を担当しており、
インフラ産業に従事するエッセンシャルワーカー向けの転職・採用プラットフォーム「プレックスジョブ」の改善や集客に関わる意思決定や施策の実行を担当しております。
今回の記事は、プレックス及びプレックスジョブにご興味を持っていただいた方に、企業とプロダクトが目指している世界、それに対しての現状や課題、弊社が候補者様に提供できるものについて少しでも理解が深まる記事になればと思っております。
簡単な自己紹介
主題をお話する前に簡単に私の経歴をお伝えすると、新卒でナイル株式会社というデジタルマーケティング を主軸にしたコンサル・事業を行っている会社に入社し、SEO を中心としたデジタルマーケティング のコンサルティング を担当した後、プレックスに5人目のメンバーとして入社しました。
プレックスに入社後は、下記のような役割を担当してきました。
求職者様の集客するためのメディアの立ち上げ
自社採用・人事機能の立ち上げ
採用広報機能の立ち上げ
人材紹介事業部の業務改善
新規領域の人材紹介事業の選定
個人としてはあまり役割にこだわりがあるタイプではなく、目的に対して自分がバリューを発揮できるのであればOKというタイプのため、このような経歴を歩むことになりました。
プレックスが5人→150人くらいの企業になるまでの様々な酸いも甘いもある経験を積み重ね、今はプレックスジョブで目指す世界の実現に向けて、開発、セールス、カスタマーサクセス、他事業などとの連携を取りつつ、プロダクトや集客の改善に取り組んでいます。
プライベートでは最近はとうとうゲーミングPCを購入し、valorant、信長の野望 、civilization の練習に勤しんでおります。
プレックスという企業がどういう世界を目指しているか
まずプロダクトが目指す世界のお話の前に、プロダクトの上段の概念にある企業がどういう世界を目指しているのか、という点についてお伝えできればと思います。
ざっくり「自分たちが解決できると仮説立てられる中で、大きな課題を手法や領域に縛られず解決していこう」という、いわゆるマーケットの課題から事業を始めるタイプの企業だと大枠で捉えていただければ良いかと思います。
具体的に、現在のプレックスは「日本を動かす仕組みを作る」というミッションを掲げており、下記のような事業を展開しています。
物流領域の人材紹介事業
エネルギー領域の人材紹介事業
製造領域の人材紹介事業
エッセンシャルワーカーのダイレクトリクルーティングサービス(プレックスジョブ)
M&A 仲介事業SaaS 事業
ミッションを少し具体化して解釈すると、「日本を動かすくらいのインパク トがある産業の課題に対して、事業という仕組みを使ってより良くしていく」といった意味があり、現に今取り組んでいる事業も、領域やビジネスモデルに縛られず、自分たちが解決すべき、解決できると信じる領域に対して始めた事業になっています。
今後企業の成長次第ではミッションの変更もあるかとは思いますが、プレックスが現時点で見えている将来としては、多種多様の産業や課題に対して、ビジネスで解決していくことを続けていこうと考えている企業で、今後も新たな事業・プロダクト・サービスを生み続けていこうとしています。
プレックスという企業全体にご興味がある方は採用ピッチ資料 をご覧ください。
プレックスジョブの目指す世界と現在地
「日本を動かすくらいのインパク トがある産業の課題に対して、事業という仕組みを使ってより良くしていく」企業の中で、プレックスジョブが目指す世界は「エッセンシャルワーカーNo.1の採用プラットフォーム」になります。
具体的に「エッセンシャルワーカー」とは、物流、エネルギー、製造など人の生活の基盤となる産業で働いている方々を指しています。エッセンシャルワーカーを採用するすべての企業様、すべてのエッセンシャルワーカー様にとって「プレックスジョブを使えば、早く、効率的に、双方の希望を満たした採用・転職ができる」という世界を目指しています。
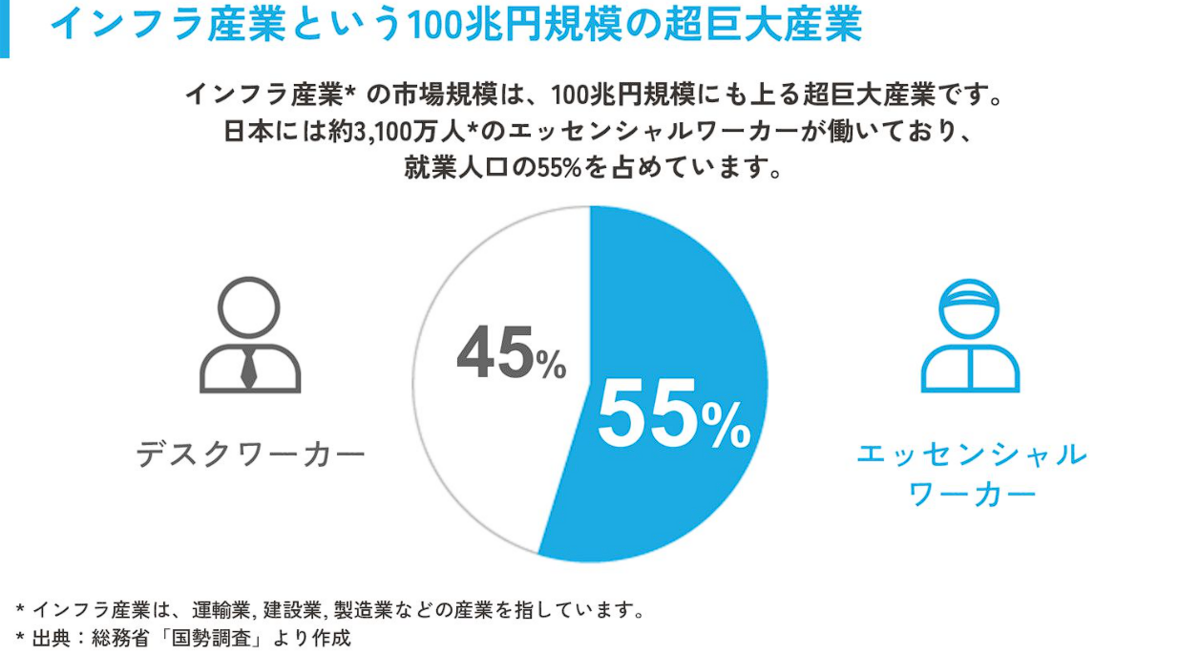
エッセンシャルワーカーは日本全国で3,100万人、エッセンシャルワーカーが関わる産業の市場規模は100兆円を超えると言われており、まさしく日本を動かしている方々、産業に対して、採用・転職の課題を解決するプロダクトになるべく、プレックスジョブが存在しています。
エッセンシャルワーカーの市場規模
2023年7月時点、弊社では累計約38万人の求職者様からの登録がありますが、エッセンシャルワーカー全体で見ると約1%、契約事業所数も12,000と、市場の大きさを鑑みるとNo.1採用プラットフォームへの道のりとしてはまだスタート地点とも言える状態にあり、多くの課題、成長余地が残されています。
ただ、エッセンシャルワーカーの採用市場の状態としては、人口減少や高齢化で採用が難しくなった流れに応じて、変化が起き始めている時期と言えます。
恐らく、この記事を読まれている方はIT系企業などに属していたり、営業/マーケティング /エンジニアといった職種の方かと思いますが、そういった方々が転職する際は人材紹介、ダイレクトリクルーティング、リファラ ル、SNS をメインの転職手法として活用し、ハローワーク や求人媒体で転職先を探すといったことは少ないかと思います。
IT系職種を採用する企業側もハローワーク や求人媒体だけでは採用が難しく、様々な採用チャネルを駆使してなんとか採用計画を達成するような状況です。
しかし、物流のドライバー採用では、ハローワーク での求人募集、紙/Webの求人広告が未だに多く活用されており、人材紹介やダイレクトリクルーティングは聞いたこともないという企業様や求職者様の方が割合としては多いです。
歴史を遡ると営業やエンジニアなどの職種も、日本の労働人口 が多く、採用市場の企業側のパワーが強かった時代は、ハローワーク や求人媒体がとても強力な採用手法だったと思いますし、ダイレクトリクルーティングという概念も存在していませんでした。
しかし、労働人口 の減少、採用競争の過激化、テクノロ ジー の進歩に伴い、企業と働き手のパワーバランスや情報格差 に変化が起き、採用手法が多様化したという歴史があると捉えています。そして、このような採用手法の変化が、エッセンシャルワーカーが働く領域にも今後起こると考えています。
人口減少と社員の平均年齢の高齢化が重なり、従来の採用手法では採用が足りず、企業が働き手に対して能動的に採用活動を仕掛けていくトレンドが、ドライバーや電気主任技術者 、製造職などの領域に広がっていく中で、その先頭をプレックスジョブが担える可能性があります。
数多の進歩により物質的に豊かになった現代において、人々の当たり前になっている活動・行動・トレンドを変えることができる領域はそう多くはないと個人的には感じていて、その大きな変化を動かす中に身を投じる経験は一定のやりがいや楽しみがあるのではないかと思います。
そして、エッセンシャルワーカーのNo.1採用プラットフォームというだけでも、とても先の長い話ではありますが、日本全体で見たマクロトレンドも踏まえると、プレックスジョブの「エッセンシャルワーカーのNo.1採用プラットフォーム」というミッションも更新される可能性が高いと見立てています。
現在のエッセンシャルワーカー、インフラ領域は「人が足りないから採用をしたい」という文脈が強いですが、人口減少や技術進歩が進むに連れて、
経験者が採用できないから、未経験でも活躍できる教育環境を整えなければいけない
採用しても退職を減らさなければそもそもの労働人口 が足りない
退職が抑えられても労働人口 が足りないから業務を効率化が必要
といったように、大きなトレンドに対してマーケットの課題認識や緊急度が変化していくことが想定されます。
そのようなマーケットの変化に合わせて、採用というプラットフォームから定着、働き手のパフォーマンス向上、業務効率化など、プロダクトが提供する価値の範囲、大きさが広がっていく可能性を秘めていると考えています。
また、採用というアプローチから入ることで働き手と企業との関係性、データなどを集めることができますので、採用以外の事業に取り組む際に顧客の課題の解像度を上げる上でも、より早く、濃いインプットや示唆を得ることができます。
今後、様々な可能性の広がりを秘めたエッセンシャルワーカー、インフラ領域というマーケットでは1つずつ大きな山を乗り越えていかなければならないため、まず最初に目指す世界として、エッセンシャルワーカーの採用No.1プラットフォームになることが現時点でのプロダクトのミッションとなっております。
プロダクトミッション実現に向けた直近の登り方
プロダクトのミッションに向けて、そこに到達するための道筋は無限にありますが、その中から現時点で最も速く到達できると信じられる仮説が、直近の事業戦略、プロダクト戦略となります。
現時点で、という但し書きをつけているのは、プロダクトのフェーズや組織のフェーズ的に、直近1ヶ月で得たインプットや、新たに入ったメンバーの活躍により、より良い仮説が出てくることが多いためです。
直近取り組むべき仮説としては、「企業様の採用活動において、サービス利用のハードルを下げる」というポイントをテーマとしています。
「採用No.1プラットフォーム」は企業様と求職者様という2者のユーザーのニーズが満たされることで達成できるミッションになっています。そのため、両方のニーズを同時に満たすことを考えると、逆にどちらも中途半端になってしまうリスクがあります。
そこで2023年の第1四半期では求職者様に向けた集客やプロダクトの改善をメインに進めて一定の進捗があったため、2023年の第2四半期では企業様に向けたプロダクトの改善を進めていこうという方針になっています。
「サービス利用のハードルを下げる」という方針に決めた理由としては、大前提としてプロダクトやサービスモデルに対して馴染みがない企業様がとても多いからです。
そのため、少しでも分からないことや既存のオペレーションよりも大変だと感じると、離脱が起こってしまう可能性が高く、いち早く新しいサービスを取り入れていただいている企業様が離れてしまうことは今後のマーケットへの影響を踏まえても避けておきたいところです。
そこで、まずはダイレクトリクルーティングというプロダクトに馴染みを持っていただき、今の採用活動のオペレーションよりも早く、効率的に採用ができる体験をしていただくことを1歩目として設定し、直近の方針としています。
具体的には、求職者様とのメッセージのやり取りを行うメッセージ機能の改善、選考の進捗を確認・記録できる選考管理画面の使いやすさの改善、採用活動のオペレーションを効率化できる機能の開発などを中心に取り組んでいきます。
一定の機能開発が進んだ後は、ドライバーなど現在弊社がメインで支援している職種以外のエッセンシャルワーカーへの支援を広げ、エッセンシャルワーカー内での人員配置の最適化を行っていくなど、プロダクトが与える影響範囲の拡張を進めていこうと考えています。
プロダクトミッション実現に向けての課題
大きく分けて3つの課題感があります。
1つ目は、「企業様、求職者様からダイレクトリクルーティングという手法及びプロダクトの理解を得る」ということです。
顧客にとって新規性の高いサービスは、なんとなく怪しく見えたり、費用対効果などが読みづらかったりと導入の難易度が高いです。そのため、セールスやマーケティング 活動を通じてプロダクトの価値を理解してもらい、実際に使って価値を享受する経験を積んでもらうことが重要になります。
その中でプロダクトチームとして取り組むポイントは、「軽く触ってみたけどよくわからないな」「使ってみたけど他の採用チャネルより大変だな」などといった、新しいプロダクトに馴染む1歩目のハードルを乗り越えることがとても重要になると考えています。
2つ目は「産業、職種ごとの特徴や傾向を捉えてプロダクトを最適化する」ということです。
具体的には、ドライバーを採用したい企業様と電気主任技術者 を採用したい企業様では知りたい求職者様の情報が異なっています。同じように求職者様側にとっても、企業様について知りたい情報がドライバーと電気主任技術者 では異なります。
そのようなユーザーのセグメントごとに違うニーズを、プロダクトとしてどのように捉え、機能や実装を行っていくかという点は、弊社のプロダクトが成長するに連れて出てくる課題になると考えています。
また、トラックドライバーから製造オペレーターへなど、異職種、異産業への転職というのも増えてくることが予測されます。その際の企業様・求職者様データベースの取り扱いをどうするか、管理画面をどうするかなど、将来的な広がりを踏まえつつ、短期的に必要なもの、長期短期のバランスを捉えた開発が必要になります。
3つ目は「顧客が想定していなかった選択肢の提案を行えるようになる」という点です。
企業様、求職者様は同じ産業や職種への知見がとても深いです。それは、基本的に同産業同職種への転職がスタンダードな世界で、ドライバーはドライバーへ転職をするというのが一般的なためです。
そのため、企業様もドライバーであればどういう物を運んでいたら自社にフィットするかなどは、過去の経験から判断することができます。ただし、ドライバー以外の仕事をやっていた人が自社で活躍できるかという点については、実際採用や入社の経験が多くなく、判断が難しいケースがあります。
そこで、プレックスジョブが得てきたデータを活かして「こういう職種の人はドライバーで活躍する傾向がある」などの提案を行えると、企業様に対して今までの採用手法では出会えなかった人に出会える可能性があります。また、求職者様も同じく、自分で探していたら出会えなかった企業に出会う機会をプレックスジョブが提供できるようになるとミッション達成により近づくのではないかと思っています。
プレックスジョブプロダクトチームで働く方に弊社が提供できるもの
弊社及びプロダクトとしての現在、想定している未来についてお話してきましたが、個々人のキャリアや人生において何を提供できるかについて、あくまで私の主観的な話にはなりますがお伝えできればと思います。※報酬面などは他で記載があるので、どちらかというと非金銭報酬や定性的なお話をメインにさせていただきます。
マーケットに新しい常識を作る経験
これは前述した通り、ダイレクトリクルーティングが浸透していないマーケットに普及していくという文脈で、影響や変化の大きさ自体にやりがいを感じる方にとっては面白い経験になると思っています。
マーケットインでビジネスを構想し、エンジニアリングで実現する組織
せっかく開発したプロダクトや機能も使われないと事業を継続して運営していくことも、改善を回すことも、価値を生み出した実感も感じづらいものです。そうならないようにセールスやマーケティング 、プロダクトマネージャーがビジネスとしてニーズがあるかどうかを検証していきます。
ビジネスサイドとエンジニアリングサイドという分断はプレックスにはなく、「顧客への価値提供とビジネスとして成り立つか」を目的とした1つの組織であり、その中の役割分担があるという考え方の組織になっているため、優劣や貴賤はなく、相互に尊重しあい、目的達成のために向かう組織になっていると感じています。
ビジネスモデル、マーケットごとの違いを知ることで、自身の知見に深みを出せる
ビジネスモデルやマーケットが異なるものの、セールス、マーケティング 、開発などの職種は共通して存在しています。例えば、同じ「セールス」という職種にしても、どういう営業リストを作るか、どういう営業トーク スクリプト を作るかなどは、顧客の属性、事業・プロダクトの状態などによって大きく異なります。
そのような各事業での成功施策、失敗施策の背景や施策の具体をインプットし抽象化すると、成果への関連性が高い共通要素が浮かび上がってきます。そして、共通要素を自分が担当する事業やプロダクトに当てはめて改善と検証を繰り返すことで、徐々に成功確率が高まっていき、自身が担当する役割や業務における再現性を持てるようになり、新たな事業やプロダクトであっても、初速から精度高く施策を当てられるようになってきます。
プレックスでは複数事業経営のスタイルのため、役割や業務の学びのサイクルを速く、大量にインプットすることができるため、知的好奇心や成長実感を得やすい環境になっているかと思います。
最後までお読みいただき、ご興味を持っていただけた方に
企業としてもプロダクトとしてもまだまだ発展途上ではありますが、目指している世界や環境についてご興味をお持ちいただけた方はぜひ一度PLEX メンバーとお話の機会をいただけたら嬉しいです。
複数の事業や職種での募集がありますので、プレックスジョブ以外での可能性も含めてお話ができると思いますので、気軽に下記からご応募ください!
エンジニア職向けカジュアル面談フォーム
docs.google.com
ビジネス職求人情報
plex.co.jp