はじめに
はじめまして、プレックスの栃川と申します。
2023年12月に株式会社プレックス(以下、プレックス)にエンジニアとして入社しました。
早くも入社して3ヶ月経ったので、自己紹介を兼ねて入社経緯や入社してからの感想などをまとめておきたいと思います。
一人でも多くの方にプレックスに興味を持っていただけると嬉しいです。
自己紹介
改めて栃川と申します。27歳の社会人4年目になります。
私の経歴は下記の通りです。
| 年月 | 経歴 |
|---|---|
| 2020年4月 | 私鉄企業へ新卒入社 。情報システム担当してました。 |
| 2021年7月 | スマサテ株式会社にエンジニアとして入社。 |
| 2023年12月 | プレックスへエンジニアとして入社。 |
実は、新卒入社した会社ではエンジニアではなく情報システム担当として働いていました。
情報システム担当と聞くとあたかもシステム関連の仕事をしていそうですが、 基本的には議事録作成や人事異動に伴うPCのセットアップなどの雑務中心の業務をしていました。
そんな畑違いの業界から急にエンジニアへの転向したのは、たまたま一緒に働いていたエンジニアの方から、Progateというプログラミングの学習サイトについて教えてもらったことをきっかけでした。
プログラミングを通じて物を作る楽しさを知ってから「自分もエンジニアになってなんか作りたい!」と強く思うようになりました。
その後、エンジニアになるべく新卒入社した会社を1年で退職し、前職にあたるスマサテ株式会社にエンジニアとして入社しました。
スマサテ株式会社では、フロントエンド・バックエンド問わず幅広く開発に携わりました。 当時はマンションの一室がオフィスで、まさにスタートアップ!という感じで働かせていただきました。
今でもこの会社で働けたことは誇りです。
2年半ほどお世話になった後、プレックスに転職しました。
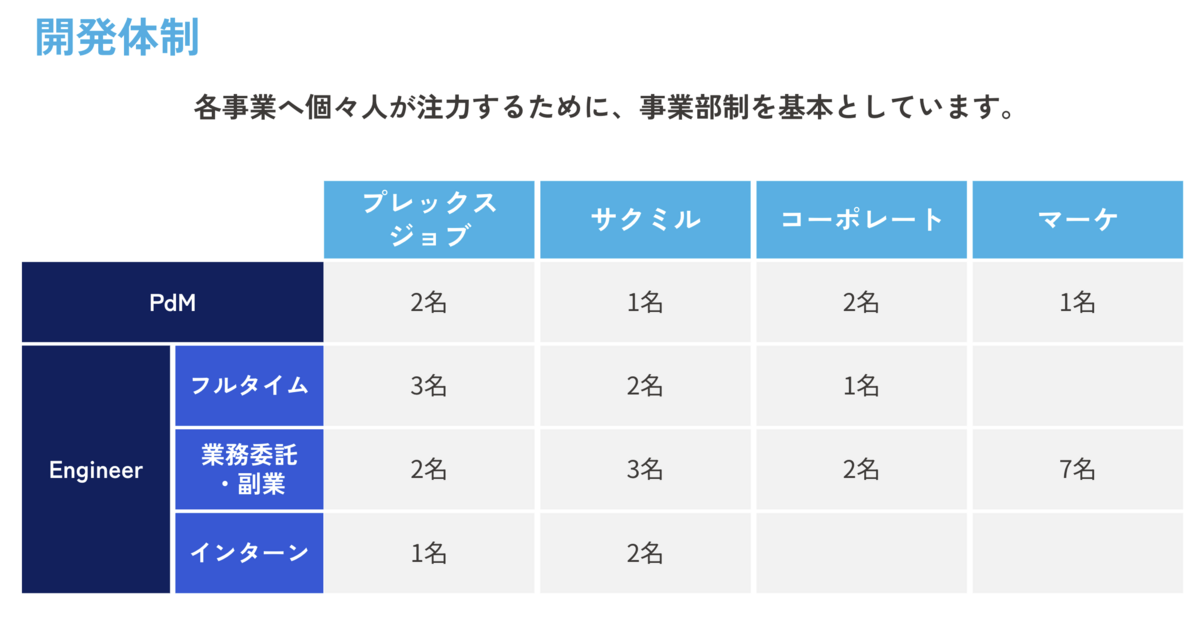
プレックスではSaaS事業部に所属し、建設業に特化した業務管理クラウドのサクミルの開発に従事しています。
プレックスに入社した理由
「この環境に飛び込んだら、とんでもない苦しみと引き換えに大きな成長を得られるかも!」
それが決め手となり、プレックスに飛び込むことを決めました。
私が転職活動で大事にしていたことは2点です。
- 事業が成長していること
- プロダクトが面白いこと
これは自身の働くモチベーションになるので重要視していました。 しかし、これらを満たす企業は何社かありました。
その中でプレックスを選んだのは、配属される部署のテックリードの方とお話しした時にこう思ったからです。
「やばい....この会社に行ったら過去の経験は何も通用しないな.....絶対苦しむな.....うん、逃げよう!」と(笑)
プレックスのエンジニアは、「正しい問いが何かを徹底的に考え、正しい意思決定をすること」が求められます。
例えば、PdMから機能開発の要望があった場合、エンジニアはその機能が「いつ・どこで・誰が・何を・どのように・なぜ」必要になるのか全て洗い出し、現状と理想のギャップから生まれる根本的な問題を正確に把握します。
その結果、問題に対してより最適な答えがあれば、エンジニアが主体となってPdMやセールスの方へ提案を行い、正しい意思決定を導き出します。
今まで「求められた機能を忠実に再現していく」ことをしてきた自分にとっては、 エンジニアが企画段階から意思決定をする環境は未知の領域です。
もし、この未知の領域に飛び込む決断をすれば、相当苦しむだろうなと全身は拒絶反応を起こしまくっていました。
一方で「この環境で働いた1年後の自分はどうなっているんだろう」と、心がとても高揚したのを今でも覚えています。
とても悩んだ末、まだ見ぬ自分に会ってみたいというワクワク感を抑えきれず、新たな挑戦に身を投じることを選びました。
入社してからの感想
徹底して思考しきる「やばい」文化
入社して3ヶ月目までは脳が溶けそうなくらい脳をフル回転させていました。 (ちなみに今も溶けそうです)
なぜなら、設計レビューしてもらうと下記のようなことを普通に質問されます。(ごく一部です)
- タスクの背景にあるものはなんだろうか。
- 背景に対してどんな課題があるのか
- 課題に対してどんな意思決定をしたのか。
- その意思決定で得られたことはなにか
- その意思決定で失うことはなにか
- その意思決定は、どの立場にたった意思決定なのか
- その意思決定の前提が崩れるときはどんな条件か
こんな感じで、どんなに小さいタスクでも徹底して思考しきります。 入社してすぐのフィードバックで「それ、仕事したとは言えませんよ」と指摘を頂いたことも記憶に新しいです(笑)
最初はとても苦労するかもしれませんが、ただの作業員ではなく、意思決定できるエンジニアを目指す人にとってはこれ以上ない「やばい」環境なのではと思います。
当たり前が「すごい」環境
プレックスではインターン生を含め優秀な方が本当に多いです。
ゆえに「当たり前の基準」が極めて高いです。
入社当初は、この当たり前の基準の高さに「すごい」を連呼していました。
例えば、仕事の進め方についても「キーボードから手を離した時点で負け」と言われるほど生産性にこだわっていますし、 「言葉にできないことは全て0点」と言われるほど、言語化や解像度の高さにこだわっています。
他にも、息をするように自己研鑽し、情報共有していくことも当たり前として根付いています。
エンジニア界隈で話題になるような話題は、どのSNSよりも早く、誰かがSlackでシェアしてくれます。 勉強会やエンジニアイベントも定期的にあります。
そのため、自分だけでは広げきれない興味・関心の範囲を一気に広げることができます。
こうした当たり前の基準が高いというのは、プレックスならではの良さだと思います。
まさに、「すごい」環境だと思います。
成長が「激アツ」な事業
「事業成長半端ない」です。
入社して何よりも驚いたことです。
「記録達成!」や「連続受注!」といった嬉しいワードが毎日のように社内で聞こるほど事業が伸びています。
事業が急成長していく中で当事者として参加できることは滅多にないので、このタイミングで入社できた運の良い自分に感謝しかありません。
事業が成長していると、やらないといけないタスクも刺激的で面白い仕事ばっかりなので、かなり「激アツ」です。
最後に
入社してから3ヶ月しか経っていませんが、プレックスはとても恵まれている環境だと心底感じています。
プレックスについて語り出すと、かなり長文になりそうなので続きは他の新人の入社エントリーにバトンタッチしたいと思います。
最後にはなりますが、プレックスではソフトウェアエンジニア、フロントエンドエンジニアを募集しています。
もしこの記事を読んで、一緒に挑戦してみたいと思った方がいましたら是非ご連絡をお待ちしています!!